Speed up your fuzzfarm: fast hit tracing
The fuzzing methodology introduced by Charlie Miller [1] was widely adopted in the security industry, as it is indeed an effective and low cost method of finding bugs.

The idea is:
- collect a lot of sample files
- let your target application parse them all
- collect the set of basic blocks executed for every file
- calculate the minimal set of samples that covers all of the collected basic blocks
- flip random bytes in files from that set and wait for a crash
It’s a simple process, but all implementations I heard of suffer from an interesting performance bottleneck in the basic block tracing part.
If your tracer takes >1min per file, you can speed it up to take only few seconds, with just a few simple observations.
Problems
The tracing part is generally implemented like this:
- instrument the binary with PIN and install a common hook for every BB
- when a BB is executed, control is transferred to the hook, which stores the BB address in a “fast” data structure implementing a set, a like red-black/avl tree.
- run the application on a sample file and terminate it when the CPU usage drops below some cutoff value.
There are few problems with this approach, but they are easy to solve.
First, let’s distinguish between tracing and hit tracing. In both cases we will assume basic block (BB) granularity.
1. During tracing, we are interested in collecting an ordered sequence of BBs, so we want to know which BBs were executed and in what order.
2. During hit tracing, we are only interested in collecting a set of executed BBs, so we don’t care if a BB was hit more than once.
From this point, “tracing” should be interpreted as 1, and “hit tracing” as 2, the same goes for “tracer” and “hit tracer”.
For example, consider the following function:
a:
dec eax
jnz a
b:
test eax, eax
jz d
c:
nop
d:
no
Tracing that example for eax=3 would produce a list: [a,a,a,b,d], and hit tracing, a set: {a,b,d}.
It’s easy to see, that when implementing a hit tracer, hooks can be dynamically removed as soon as a BB is executed. Indeed, since we save BBs in a set, any attempt to store the same one more than once is a waste of time.
To make the bigger picture clear:
- install hooks in all BBs
- when a BB is hit, execution transfer to the hook
- hook saves the BBs address in a set
- hook uninstalls instelf from the hit BB
- hook transfers control to the originating BB
We’ve eliminated the first problem of the MM (Miller’s method ;)). The second problem is termination: when should we stop collecting BBs?
Watching the CPU is counterproductive: if the processor is busy, it has to be in some kind of a loop (unless you feed it with gigabytes of consecutive NOPs :p). If it’s in a loop, it’s pointless to wait for an extended period of time, because you’re going to collect all of the loops’ BBs at the very beginning anyway.
A better (faster) approach is to watch how many new BBs we collected in a predefined timestep. To be more precise, let 

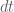

This heuristic is inferior in situations where the target spends a lot of time in disjoint loops: if we have loop1(); loop2(); and loop1 takes a while, then the target will be terminated early, before reaching loop2.
Implementation
There are few ways to implement the hit tracer:
– script your favourite debugger
– use PIN/DynamoRIO
– write your own debugger
Scripting ImmDbg, WinDbg, or PyDbg is a bad idea: with >100k breakpoints these tools are likely to fail :). PIN is probably a good tool for this task (it’s a Binary Dynamic Instrumentation tool, after all ;)), but we’ll focus on the last option.
Assuming our target is not open source, we need to find a way to hook all BBs at the binary level. The first solution that comes to mind is:
- use IDA to statically collect all BBs
- patch all of them with a jump to our hook
There are two problems with this approach:
- jumps have to be long (5 bytes), so they might not fit into very small BBs
- IDA isn’t perfect and can produce incorrect results. Patching an address that isn’t a beginning of a BB can (most likely will) lead to a crash.
Problem 1
Solving problem 1 can be either simple and inaccurate or complicated but accurate. A quick solution is to ignore BBs shorter than 5 bytes and patch only the bigger BBs. This can be ok, depending how many BBs are going to be discarded: if just a few, then who cares ;).
If there’s a lot of them, we’re going to use a different approach. Instead of patching with jumps, we can patch with int 3 (0xCC) — since it’s only one byte, it will fit everywhere ;).
When a BB is executed, int 3 will throw an exception that needs to intercepted by our external debugger. This introduces a penatly that’s not present in the jump method: kernel will have to deliver the exception from the target application to the debugger, and then go back to resume execution of the patched BB. This cost is not present, when a jump transfers execution to a hook inside the target’s address space, but it turns out that this delay is negligible.
The debugger contains the hook logic including a data structure implementing a set. Notice that we can be faster, although by a constant factor, than AVL/RB trees. Having a sorted list of addresses of BBs (call it L), we can “implement” a perfect hash [2]: Hash(BB)=index of BB in L, so our set can be a flat table of bytes of size = size(L). The “insert(BB,S)” procedure is just: S[H[BB]]=1, without the cost of AVL/RB bookkeeping/rebalancing :). The cost of Hash(BB) is obviously 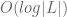
Problem 2
Solving 2 might seem to be a matter of observing where the patched application crashed and reverting bytes at that address to the original values. That might work, but doesn’t have to :). If a bad patch results in a bogus jump, the crash address will be completely unrelated to the real origin of the problem!
The correct solution is a bit slow:
def check_half(patches):
apply_patches(exe, patches)
crashed = run(exe)
if crashed:
revert_patches(exe, patches)
if len(patches)>1:
apply_non_crashing(patches)
def apply_non_crashing(patches):
fst = half(0, patches)
snd = half(1, patches)
check_half(fst)
check_half(snd)
Starting with a clean exe and a list of patches to apply, we split the list into halves and apply them in order. If the patched version crashes, we revert made changes and recurse with one of the halves. At the tree’s bottom, if a single byte causes a crash, we just revert it and return.
It’s easy to see, that this algorithm has complexity 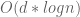


Benchmarks
I didn’t bother comparing with available (hit)tracers, since just judging by the GUI lag, they are at least an order of magnitude slower than the method described. The executable instrumented with int3s has no noticeable lag, compared to the uninstrumented version, at least on manual inspection (try clicking menus, etc).
We’ll benchmark how much (if at all) the monotonicity heuristic is faster than just waiting for a fixed amount of time T. This models a situation where the target takes ~T seconds to parse a file (using ~100% CPU).
Follow these steps to repeat the process yourself:
- download this
- download the first 150 pdf files from urls.txt (scraped with Bing api ;)), delete 50 smallest ones, and place what’s left in ./samples/ dir
- run SumatraPDF.exe and uncheck “Remember opened files” in Options (otherwise the results would be a bit skewed — opening a file for the second time would trigger cache handling code)
- run stats.py and wait for results 🙂
Files in the archive:
- SumatraPDF.exe – version without instrumentation (no int3 patches)
- patched.exe – instrumented version
- debug.exe – debugger that’s supposed to intercept and resume exceptions raised from patched.exe
- urls.txt – urls of sample pdf files
- stats.py – benchmarking script
The debugger takes few parameters:
<exe> <sample file> <dt> <c> <timeout>
where exe is the instrumented executable, sample file is the file to pass as a first parameter to the exe, dt and c have the meaning as described above, and timeout is the upper bound of time spent running the target (debugger will terminate the target, even when new BBs are still appearing). dt and timeout are in milliseconds, c is a float.
Methodology
Every sample is hit traced two times. First time, debugger is run with
parameters:
patched.exe <sample> 1000 0.0 2000
meaning there is no early termination — BBs are collected for 2 seconds.
Second time, debugger is run with:
patched.exe <sample> 200 1.01 2000
meaning the target is terminated early, if during 200ms the number of BBs didn’t
increase by at least 1%. Here’s the watchdog thread implementing this:
DWORD WINAPI watchdog(LPVOID arg){
int i, elapsed;
float old_counter=0;
elapsed = 0;
printf("watchdog start: g_c=%.02f, g_delay=%d, g_timeout=%d\n", g_c, g_delay, g_timeout);
while(1){
Sleep(g_delay);
elapsed += g_delay;
if((float)counter > g_c*old_counter){
old_counter=(float)counter;
}
else{
break;
}
if(elapsed>=g_timeout)
break;
}
dump_bb_tab("dump.txt");
printf("watchdog end: elapsed: %d, total bbs: %d\n", elapsed, counter);
ExitProcess(0);
}
It dumps the BB list in dump.txt as a bonus ;).
Results
Speed: 0.37 (smaller is better)
Accuracy: 0.99 (bigger is better)
As expected, the monotonicity heuristic performs better (almost 3x) than just waiting for 2 seconds, for the price of 1% drop in accuracy.
Note that the 2s timeout is arbitrary and supposed to model a situation when the target is spinning in a tight loop. In such a case watching the CPU is (most likely) a waste of time.
TL;DR
If you want your hit tracer to be fast, then:
- remove the BB hook after first hit
- use simple data structures
- for termination, consider different conditions than watching the CPU
References
1. Charlie Miller, 2010, Babysitting an army of monkeys: an analysis of fuzzing 4 products with 5 lines of Python, http://tinyurl.com/cwp5yde
2. Perfect hash function, http://en.wikipedia.org/wiki/Perfect_hash_function

Cool stuff, how have you patched the binary with int3? Do you have a script for doing for other applications?
Idapython for generating the BB list + python scripts for patching. I’ve added the .offsets section / .stubs section manually (and then filled them with a script)
this is cool. one thing I didn’t quite get – where are you storing the original instructions that you’re patching over with CC’s? is that in the .stubs/.offset section of the exe?
.offsets section contains addresses of all patched basic blocks and the .stubs section trampolines for uninstalling hooks. Trampolines restore the original byte and jump back to the BB, to resume execution.
The .offsets section is just a sorted list of BB addresses, so that every BB has a unique number. Debugger reads that section on the first int3 and later uses it to find which trampoline to jump to. It’s possible because trampolines have the same ordering as addresses in .offsets, plus all trampolines are the same size S, so if a BB has id X, then its trampoline has address STUBS_SECTION+X*S 🙂
Bigger picture:
BB (hooked) -> int3 -> debugger (finds the BB’s id) -> trampolines[id] (uninstalls hook) -> BB (no hook)
awesome, thanks for that!
Awesome work!
There are some other solutions along the lines of “- write your own debugger”.
1) Make your own emulator to follow BB branching using the CPU single step mechanism.
This is for example how HBGary’s much hyped “Responder” works.
In It’s inner workings it’s basically some kind of recorder (for both code and data), but in this case only thing you record is BB traversal stuff.
It has an advantage of emulating access to the trap flag too so if the application is looking for single stepping you can hide it.
You’d think stepping every instruction like this would be slow though (see below).
2) Use the CPU hardware branch trace feature.
A special debugger feature of most current x86 CPUs to monitor each branch instruction (both calls and jumps).
There are two standard setups:
A) One is setup via MSR registers (both Intel and AMD) to cause an exception on every branch (jumps and calls).
It incurs the overhead of a an exception/trap per branch.
I’ve tried this and it works well, just needs to be done in R0 space (see below).
B) The other (Intel only) is the CPU “DS Store” branch recorder feature.
It fills a special user defined buffer with branch data. When it hits a set limit it will exception to allow for processing of the buffer et al.
I’ve only got this to partially work, it’s apparently more tied to more then just the CPU.
Also not as flexible as the other method that gives you the state of everything when the branch occurs, this is just a recording stream.
At least it in theory it should be less CPU overhead as there is only an exception when the buffer is full.
At any rate in either method the CPU is in a special mode so there is some slow down anyhow.
A another CPU hardware way might be via some special tricks like Darawk mentions in a thread ref link below.
Use the performance monitoring buffers with a size of 1 so it fires on every “call”, maybe this or something similar could be setup to fire off on jumps too.
Like type ‘B’ though it’s only Intel or at the very least more CPU specific.
Needs a Kernel driver:
Like “Responder” and from my own research shown you really need to do this in R0.
In a simple kernel driver you replace the int1 vector directly with your own handler.
If the int1 exception belongs to you then you handle it and finish with an “iret”, else
just pass it along to the OS default handler.
+Saves on tons of overhead. Each trace exception might be raw ~100 cycles (the CPU has to save registers and other steps) vs the OS handling with it’s IPC stuff, etc., making it down into the R3 process might be 1000’s of cycles. Also avoids other problems like if you
trace into the exception handling stuff in “ntdll.dll” you’ll hang the process in loop.
Besides that the trap flag needs to be set in each thread you want to trace, it’s almost transparent to a target process.
Some refs:
http://en.wikipedia.org/wiki/Branch_trace
http://www.openrce.org/blog/view/535/Branch_Tracing_with_Intel_MSR_Registers
http://www.woodmann.com/forum/archive/index.php/t-10178.html
EDIT (paul): I removed what seem to be a bad paste.
Very cool, thanks for a detailed comment :3. Which of the methods you mention would be the fastest?
I’ve tried the one mentioned here, putting hooks, and, or int3 on every function entry.
While it is probably going to be the fastest, it’s just too error prone. IDA will give the wrong entry point for some functions and completely miss some others.
And then I made a little prototype tool with branch tracing type ‘A’ mentioned above, the CPU hardware exception on every branch trace type.
The last time I played with this it was on a single core machine. It was fast enough to work in a demanding game real time although it would drop the frame rate down to maybe 10 or so.
It might be much faster newer generation CPUs.
You have to use a kernel driver to skip the default OS handling for speed.
I did the minimal amount of processing in the int1 handler. It would mainly increment counters that were mapped 1 to 1 with the code space of interest.
I really should dust off the old project, maybe experiment with it some more, and put up the source code.
Furthermore, hey your “DeCV — a decompiler for Code Virtualizer by Oreans” is brilliant!
Love it! And it’s nice you share your awesome research like this.
And if your interested maybe we could get together on this and make sort of a “Branch Tracing toolkit” or something.
There are several parts to it. A CPU DB (identified by CPUID, model, and type, etc.), the int1 handler, and inter process com, etc.
And it could be more robust like controlling the BT features per thread. Similar with Intel does with it’s VTune drivers (I RE’ed a 32bit XP version of one).
And maybe finally get the “DS store” method working. Might have to develop it on a Linux variant since all the kernel source is available and documented. That’s where I was thinking of going next to have the needed control over the CPU and supporting chip set hardware et al.
Another challenge, at least in a “tool kit” sense is to provide some sort of R3 interface for it all. I just wanted call hit counts at the time, but then what might be really needed is to record call chains. If not in real time, then a collect/record and process/analyze later setup like “Responder”.
To me this one frontier that is not explored enough (at least not publicly), yet there is so much potential here in areas of: automated unpacking, advanced OEP finding, profiling, dynamic/automated RE tools, etc.
I sent you and email.