Solving Pimp crackme by j00ru and Gynvael Coldwind
I figured a nice tutorial would be more interesting than yet another “hello world” post, so here it goes — solution for Pimp crackme, a winning entry for Pimp my crackme contest (polish) by j00ru and Gynvael. You can download entires (all three of them) from the contest’s page. AFAIK I’m the only person who submitted a solution.
Let’s see what we are up against.

Looks nice :).
There are four columns consisting of four symbols. Each column has it own color, so that makes 16 unique symbols, easy math there :). Since serial’s length is also 16 characters, we can’t bruteforce a solution — total number of combinations is 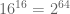
First thing we need to do is to identify a procedure that checks if the serial we provided is correct. Normally, we would look at cross-references (in IDA) for the message informing about success / failure, but in this case we can’t — crackme stores these messages as images, not strings, so we need to try something different.
Let’s try to follow execution from the beginning, to see how the main window is created, that should give us information about the window’s procedure and how it processes messages.
.text:004015BC push offset stru_40D000 ; WNDCLASSEXA * .text:004015C1 call RegisterClassExA (...) .text:00401625 push 0 ; lpParam .text:00401627 push ebx ; hInstance .text:00401628 push 0 ; hMenu .text:0040162A push 0 ; hWndParent .text:0040162C push 190h ; nHeight .text:00401631 push 190h ; nWidth .text:00401636 push esi ; Y .text:00401637 push eax ; X .text:00401638 push 90000000h ; dwStyle .text:0040163D push offset WindowName ; "Pimp CrackMe" .text:00401642 push offset ClassName ; "i" .text:00401647 push 0 ; dwExStyle .text:00401649 call CreateWindowExA
Structure WNDCLASSEXA in this case is:
.data:0040D000 stru_40D000 WNDCLASSEXA <30h, 0, offset windows_proc, 0, 0, 0, 0, 0, 5, 0, \ .data:0040D000 offset ClassName, 0> ; "i"
windows_proc is, as name suggests, the message handling procedure of the main window. Let’s look inside.
if ( Msg == WM_PAINT )
{
if ( (unsigned __int8)thread_spawned ^ 1 )
{
CreateThread(0, 0, (LPTHREAD_START_ROUTINE)paint_thread, 0, 0, &ThreadId);
thread_spawned = 1;
}
hdc = BeginPaint(hWnd, &Paint);
StretchDIBits(hdc, 0, 0, 400, 400, 0, 0, 400, 400, lpBits, &bmi, 0, 0xCC0020u);
EndPaint(hWnd, &Paint);
return 0;
}
Now, inside paint_thread:
.text:00402A18 mov eax, [ebp+var_4] .text:00402A1B mov cl, byte_40D040[eax] .text:00402A21 movzx eax, cl .text:00402A24 mov edx, 0 .text:00402A29 mov ecx, 0Fh .text:00402A2E sub ecx, [ebp+var_4] .text:00402A31 shl ecx, 2 .text:00402A34 shld edx, eax, cl .text:00402A37 shl eax, cl .text:00402A39 test cl, 20h .text:00402A3C jz short loc_402A42 .text:00402A3E mov edx, eax .text:00402A40 xor eax, eax .text:00402A42 .text:00402A42 loc_402A42: .text:00402A42 or [ebp+var_10], eax .text:00402A45 or [ebp+var_C], edx .text:00402A48 inc [ebp+var_4] .text:00402A4B .text:00402A4B loc_402A4B: .text:00402A4B cmp [ebp+var_4], 0Fh .text:00402A4F jle short loc_402A18 .text:00402A51 mov ds:serial_length, 0 .text:00402A5B sub esp, 4 .text:00402A5E push 10h ; Size .text:00402A60 push 0FFh ; Val .text:00402A65 push offset byte_40D040 ; Dst .text:00402A6A call memset .text:00402A6F add esp, 10h .text:00402A72 sub esp, 8 .text:00402A75 push [ebp+var_C] .text:00402A78 push [ebp+var_10] .text:00402A7B call check_serial .text:00402A80 add esp, 10h .text:00402A83 test al, al .text:00402A85 jz short loc_402AA4 .text:00402A87 mov ds:goodboy_flag, 1 .text:00402A8E mov eax, 41F00000h .text:00402A93 mov flt_40D034, eax .text:00402A98 push 0 .text:00402A9A call sub_4013B0 .text:00402A9F add esp, 4 .text:00402AA2 jmp short loc_402ABF
How did I knew we should focus on this part? That code just looks suspicious :). Part at the beginning is a loop with 16 (number of characters in serial) iterations, converting something from a buffer (byte_40D040) to a 64-bit number. Stepping through that code in a debugger reveals, that byte_40D040 holds characters of the serial number, “encoded” as follows:
0 4 8 c 1 5 9 d 2 6 a e 3 7 b f
So the green triangle from the first column is 0, and the purple triangle from last column is 0xC. Forcing path down to 00402A87 sets the “goodboy” flag and makes the crackme display congratulations. We are not interested in patching, as that would be too easy. Besides, authors explicitly forbid it.
We need to take a look at check_serial function. I’ll skip the part about how to actually understand the disassembly, since it’s a topic in itself, and move straight to the semantics. Here is an approximate decompilation of the serial-checking function.
//.text:004039AE
bool __cdecl check_serial2(int sn1, int sn2)
{
int param_ptr; // ST14_4@4
int v3; // ecx@19
signed int v4; // eax@19
bool v6; // [sp+0h] [bp-28h]@2
int v7; // [sp+8h] [bp-20h]@1
int opcode_ptr; // [sp+Ch] [bp-1Ch]@3
unsigned __int8 vm_opcode; // [sp+13h] [bp-15h]@4
int vm_argument; // [sp+14h] [bp-14h]@4
int vm_proc; // [sp+18h] [bp-10h]@4
int vm_result; // [sp+1Ch] [bp-Ch]@12
int vm_resulta; // [sp+1Ch] [bp-Ch]@23
int i; // [sp+20h] [bp-8h]@4
v7 = 0;
if ( sub_403950() == 0 )
{
v6 = 0;
}
else
{
sn1_copy = sn1;
sn_nibble = sn1 & 0xF;
*(_DWORD *)vm_reg4 = sn2;
opcode_ptr = 0;
while ( 1 )
{
if ( vm_code_size = 0 )
{
if ( vm_result > 0 )
{
if ( opcode_ptr + 5 * vm_result >= (unsigned int)vm_code_size )
return 0;
opcode_ptr += 5 * vm_result;
}
}
else
{
vm_resulta = -vm_result;
if ( opcode_ptr + -5 * vm_resulta < 0 )
return 0;
opcode_ptr += -5 * vm_resulta;
}
}
}
v6 = v7 == 8;
}
return v6;
}
This might be confusing at first glance, so let’s simplify it further.
// sn1 - first dword of our serial
// sn2 - second dword
// op_ptr is a pointer to current VM opcode
// vm_code is a table containing opcodes and arguments: [op1,arg1,op2,arg2,...]
// vm_reg4 - virtual register 4
op_ptr = 0;
vm_reg4 = sn2;
while(1){
vm_op = fetch_opcode(op_ptr, vm_code);
vm_arg = fetch_arg(op_ptr+1, vm_code);
vm_proc = fetch_proc(vm_op, handlers);
op_ptr += 5;
result = vm_call(vm_proc, vm_arg);
if(result == 0xBADC0FFE)
break;
if(result == 0xDEADBEEF){
if(vm_reg1 != constants[i])
return 0;
i++;
sn_part = trim(sn1, i);
}
else{
if(result >= 0){
if(result > 0)
if(op_ptr + result >= vm_code_size)
return 0;
}
else{
if(op_ptr + result < 0)
return 0;
}
op_ptr += result;
}
}
return (i==8);
Much better :). We see that there are two values with special meaning. One, 0xBADC0FFE is a signal to terminate the VM. Second one 0xDEADBEEF is a signal to compare the contents of one of the virtual registers (vm_reg1) against a constant from a table. If the comparision fails, serial is rejected (return 0).
If the value returned from vm_call isn’t one of the above magic constant, VM treats it as a jump displacement, by updating op_ptr (op_ptr += result). Before update VM checks if displacement is in correct range, as jumping after or before the vm_code buffer would result in executing trash 🙂
Notice that our 64-bit serial is split into two 32-bit parts: sn1 and sn2. sn2 is copied to VM_REG4, so it seems that only this part in mangled by the VM, as sn1 is used to set an additional variable sn_part, using function “trim”:
unsigned int trim(n, i){
int x, y;
x = 4*(i+1);
y = n<<x;
if(x & 0x20)
y = 0;
return (n & (y-1));
}
This will play a role later on.
Finally, last return statement (return (i==8)) tells us, that all 8 comparisions must succeed, otherwise crackme will reject our serial.
That doesn’t seem so bad, we just need to decompile the embedded VM code and reverse/bruteforce whatever computation it performs on sn2. We should expect some kind of trickery, since it’s unlikely that sn1 is simply ignored.
Let’s take a look at the VM handlers.
.data:0091FE20 handlers_procs dd offset handlers_proc .data:0091FE24 ; char handlers_op[] .data:0091FE24 handlers_op dd 1 .data:0091FE24 .data:0091FE28 off_91FE28 dd offset vm_mix_handlers .data:0091FE28 .data:0091FE2C ; int handlers[] .data:0091FE2C handlers dd 0 .data:0091FE2C .data:0091FE30 ; int dword_91FE30[] .data:0091FE30 dword_91FE30 dd 0 .data:0091FE30 .data:0091FE34 dd offset handlers_proc .data:0091FE38 dd 2 .data:0091FE3C dd offset vm_DIE .data:0091FE40 dd 0 .data:0091FE44 dd 0 .data:0091FE48 dd offset handlers_proc .data:0091FE4C dd 3 .data:0091FE50 dd offset vm_JMP .data:0091FE54 dd 0 .data:0091FE58 dd 0 .data:0091FE5C dd offset handlers_proc .data:0091FE60 dd 4 .data:0091FE64 dd offset vm_JZ .data:0091FE68 dd 0 .data:0091FE6C dd 0 .data:0091FE70 dd offset handlers_proc .data:0091FE74 dd 5 .data:0091FE78 dd offset vm_JNZ .data:0091FE7C dd 0 .data:0091FE80 dd 0 .data:0091FE84 dd offset handlers_proc .data:0091FE88 dd 6 .data:0091FE8C dd offset vm_mov_hostReg1_reg1 .data:0091FE90 dd 0 .data:0091FE94 dd 0 .data:0091FE98 dd offset handlers_proc .data:0091FE9C dd 7 .data:0091FEA0 dd offset vm_mov_reg1_hostReg1 .data:0091FEA4 dd 0 .data:0091FEA8 dd 0 .data:0091FEAC dd offset handlers_proc .data:0091FEB0 dd 8 .data:0091FEB4 dd offset vm_fancy_call .data:0091FEB8 dd 0 .data:0091FEBC dd 0 .data:0091FEC0 dd offset handlers_proc .data:0091FEC4 dd 9 .data:0091FEC8 dd 0 .data:0091FECC dd offset vm_mov_mem_reg1 .data:0091FED0 dd 3Ah .data:0091FED4 dd offset handlers_proc .data:0091FED8 dd 0Ah .data:0091FEDC dd 0
Handlers aren’t obfuscated in any way, so it’s easy to identify what they do by just looking at them. For example:
.text:0040301E vm_DIE proc far .text:0040301E .text:0040301E var_4 = dword ptr -4 .text:0040301E .text:0040301E push ebp .text:0040301F mov ebp, esp .text:00403021 sub esp, 10h .text:00403024 mov [ebp+var_4], 0BADC0FFEh .text:0040302B mov eax, [ebp+var_4] .text:0040302E leave .text:0040302F retf .text:0040302F vm_DIE endp .data:0091F740 vm_or_reg1_reg2 proc far .data:0091F740 mov esi, 0FFF0h .data:0091F745 cmp esi, 0FFFDh .data:0091F74B jb short loc_91F754 .data:0091F74D xor eax, eax .data:0091F74F xor edx, edx .data:0091F751 retf 4 .data:0091F754 ; --------------------------------------------------------------------------- .data:0091F754 .data:0091F754 loc_91F754: .data:0091F754 mov ebx, [edi+0FFF0h] .data:0091F75A mov esi, 0FFF4h .data:0091F75F cmp esi, 0FFFDh .data:0091F765 jb short loc_91F76E .data:0091F767 xor eax, eax .data:0091F769 xor edx, edx .data:0091F76B retf 4 .data:0091F76E ; --------------------------------------------------------------------------- .data:0091F76E .data:0091F76E loc_91F76E: .data:0091F76E mov ecx, [edi+0FFF4h] .data:0091F774 or ebx, ecx .data:0091F776 mov [edi+0FFF0h], ebx .data:0091F77C xor eax, eax .data:0091F77E xor edx, edx .data:0091F780 retf 4 .data:0091F780 vm_or_reg1_reg2 endp .data:0091F520 vm_add_reg1_param proc far .data:0091F520 .data:0091F520 arg_0 = dword ptr 8 .data:0091F520 .data:0091F520 mov esi, 0FFF0h .data:0091F525 cmp esi, 0FFFDh .data:0091F52B jb short loc_91F534 .data:0091F52D xor eax, eax .data:0091F52F xor edx, edx .data:0091F531 retf 4 .data:0091F534 ; --------------------------------------------------------------------------- .data:0091F534 .data:0091F534 loc_91F534: .data:0091F534 mov ebx, [edi+0FFF0h] .data:0091F53A mov ecx, [esp+arg_0] .data:0091F53E add ebx, ecx .data:0091F540 mov [edi+0FFF0h], ebx .data:0091F546 xor eax, eax .data:0091F548 xor edx, edx .data:0091F54A retf 4 .data:0091F54A vm_add_reg1_param endp .text:004031B5 vm_JZ proc far .text:004031B5 .text:004031B5 arg_0 = dword ptr 0Ch .text:004031B5 .text:004031B5 push ebp .text:004031B6 mov ebp, esp .text:004031B8 mov eax, ds:vm_reg3 .text:004031BD mov eax, [eax] .text:004031BF test eax, eax .text:004031C1 jz short loc_4031C8 .text:004031C3 mov eax, [ebp+arg_0] .text:004031C6 leave .text:004031C7 retf .text:004031C8 ; --------------------------------------------------------------------------- .text:004031C8 .text:004031C8 loc_4031C8: .text:004031C8 xor eax, eax .text:004031CA leave .text:004031CB retf .text:004031CB vm_JZ endp
With all handlers identified, it’s easy to write a script for IDA that disassembles the VM code. Let’s take a look at the output (scroll down to get the script).
0: [0a] vm_mov_reg1_mem 0xfffc 1: [06] vm_mov_hostReg1_reg1 0x0 2: [12] vm_and_reg1_param 0xf 3: [19] vm_shl_reg1_param 0x6 4: [09] vm_mov_mem_reg1 0x10 5: [07] vm_mov_reg1_hostReg1 0x0 6: [06] vm_mov_hostReg1_reg1 0x0 7: [0a] vm_mov_reg1_mem 0x14 8: [0b] vm_mov_reg2_mem 0x10 9: [0f] vm_cmp_reg1_reg2 0x0 10: [16] vm_add_reg1_param 0x1 11: [09] vm_mov_mem_reg1 0x14 12: [04] vm_JZ 11 13: [07] vm_mov_reg1_hostReg1 0x0 14: [08] vm_fancy_call 0x1 15: [14] vm_not_reg1 0x0 16: [08] vm_fancy_call 0x3 17: [0b] vm_mov_reg2_mem 0x14 18: [10] vm_xor_reg1_reg2 0x0 19: [08] vm_fancy_call 0x2 20: [16] vm_add_reg1_param 0xdeadbeefL 21: [17] vm_rol_reg1_param 0x7 22: [08] vm_fancy_call 0x0 23: [03] vm_JMP -18 24: [07] vm_mov_reg1_hostReg1 0x0 25: [01] vm_mix_handlers 0x0 ########## 0: [1b] vm_mul_reg1_reg2 0x0 1: [02] vm_DIE 0x14 2: [14] vm_not_reg1 0xfffc 3: [12] vm_and_reg1_param 0x0 4: [04] vm_JZ 4 5: [17] vm_rol_reg1_param 0xf 6: [0e] vm_xchg_reg1_reg2 0x6 7: [02] vm_DIE 0x10 8: [15] vm_add_reg1_reg2 0x0 9: [12] vm_and_reg1_param 0x0 10: [14] vm_not_reg1 0x14 11: [09] vm_mov_mem_reg1 0x10 12: [07] vm_mov_reg1_hostReg1 0x0 13: [08] vm_fancy_call 0x1 14: [02] vm_DIE 0x14 15: [11] vm_and_reg1_reg2 0xb 16: [15] vm_add_reg1_reg2 0x0 17: [06] vm_mov_hostReg1_reg1 0x5 18: [16] vm_add_reg1_param 0x0 19: [05] vm_JNZ 0 20: [06] vm_mov_hostReg1_reg1 0x7 21: [13] vm_or_reg1_reg2 0x0 22: [06] vm_mov_hostReg1_reg1 0x6 23: [0a] vm_mov_reg1_mem 0x0 24: [06] vm_mov_hostReg1_reg1 0x4
Second column is the instruction’s opcode. Numeric constant after each instruction is its parameter. Some instructions don’t take parameters, in which case the constant is 0.
First part of the decompilation looks nice — there is a loop with some arithmetic mangling, the usual thing you’d expect from a serial checking procedure in a crackme.
The second part looks wrong. There are premature VM_DIE instructions (we expect only one at the very end of code), jumps with nonsensical displacements, like vm_JNZ 0 (jmp $) and no-parameter instructions with parameters, like vm_NOT reg1, 0xfffc.
Answer to this mystery resides in implementation of vm_mix_handlers instruction. Try to take a look at it yourself and guess what it does, the address is 00403039. You won’t be able to debug it (or any other handler), due to some clever trickery, already described in detail by j00ru here.
Here’s a decompilation:
def mutate(handlers):
for j in range(2, len(handlers)):
k = prng()
k = (k % 0x1B)+2
t = handlers[j]
handlers[j] = handlers[k]
handlers[k] = t
return handlers
def prng():
global seed #=sn_part = trim(sn1, i)
v0 = ((10009 * seed + 31337) % 2**32) % 100000007
seed = 5 * seed + 1337;
seed = seed % 2**32
return v0
As we can see, handlers are mixed using a pseudo random number generator (PRNG), seeded with sn_part (sn_part = trim(sn1,i)) and that’s why we got garbage instead of clean code during decompilation, apparently seed wasn’t correct. The nice thing about this scheme is how the seed is computed. Each time the PRNG is used, there are only 16 possible disassemblies, since after each vm_mix_handlers, only one nibble from sn1 is copied to sn_part (scroll up for implementation of trim).
It’s clear what we need to do. We should generate all 16 possible disassemblies and recognize the correct one automatically. I used only two heuristics: presence of premature VM_DIE instructions and presence of no-parameter instructions with params, like OP reg1, reg2, param.
I won’t paste the disassembled code, as it’s rather repetitive — there are few loops with arithmetic operations on sn2, nothing extreme :). The important thing is, there are three possible values of sn1, resulting in correct VM code being executed: 0x39845c67, 0xc9845c67, 0xd9845c67.
With first part out of the way, let’s work on the second one. After porting the decompiled code to C, we notice that reversing parts of the algorithm may be tricky:
inline int vm_fancy0(int a1)
{
signed int v2; // [sp+4h] [bp-Ch]@1
int v3; // [sp+8h] [bp-8h]@1
unsigned int i; // [sp+Ch] [bp-4h]@1
v2 = 63689;
v3 = 0;
for ( i = 0; i <= 0x1F; ++i )
{
v3 = v2 * v3 + i * a1;
v2 *= 378551;
}
return v3;
}
inline unsigned int round0(unsigned int sn2, unsigned char *mem){
unsigned int r1, r2, hr1,tmp1,tmp2;
tmp1 = tmp2 = 0;
r1 = sn2;
hr1 = r1;
r1 = r1 & 0xF;
r1 = r1 << 6;
tmp1 = r1;
r1 = hr1;
while(1){
hr1 = r1;
r1 = tmp2;
r2 = tmp1;
r1 += 1;
tmp2 = r1;
if(r1-1 == r2)
break;
r1 = hr1;
r1 = vm_fancy1(r1);
r1 = ~r1;
r1 = vm_fancy3(r1);
r2 = tmp2;
r1 = r1 ^ r2;
r1 = vm_fancy2(r1);
r1 += 0xdeadbeef;
r1 = rol(r1, 7);
r1 = vm_fancy0(r1);
}
r1 = hr1;
// mix_handlers 0
// cleanup
tmp1 = 0;
tmp2 = 0;
return r1;
}
vm_fancy* functions are similiar — they are all hard to reverse and loop the same number of times (32). There are eight rounds (8 functions similiar to round0), but porting them all to C isn’t really necessary. Since all of them take the same dword as an input (sn2), we can bruteforce only first two. Chance that a particular value passes first two checks, but not all eight is negligibly small, assuming all rounds are indepented and random bijections.
Bruteforce isn’t out of reach. To check all 32-bit values, we need to perform about 

Solution
First dword is one of: 0x39845c67, 0xc9845c67, 0xd9845c67.
Second dword is: 0xaed6334b.
")
Fun facts
1. There are few 32-bit values for sn2 that pass more than one, but less than eight of crackme’s checks. That seems surprising, because assuming that all rounds are random and independent bijections, probability of finding a value that passes two checks is equal to 
2. With some dedication it might be possible to put the crackme in a inifinite loop. Since bad sn1 results in garbage code being executed, it is probable that one of the disassemblies include an undonditional vm_JMP instruction with negative parameter. With some luck it could hang the VM (assuming there would be no premature vm_DIE instructions before vm_JMP and no jumps over it). I talked with j00ru about this, and this problem was anticipated, but protecting against it was considered to be an overkill, after all, it’s just a crackme, and bruteforcing for such a magic looping dword seems pointless :).
You can get the decompiler script and the bruteforcer from my github account here.

What can I say… great work! 🙂
Nice work! Another approach to the 2nd part is to try ro generate SMT equations for the vm_fancy* functions and round0() and then use a solver like Z3 to find input values that generate the correct solution.
@Mark:
SAT solvers are not so smart when faced with such problems, they are much slower than an optimized bruteforcer actually. Try using Z3 to find a “collision” for CRC32.
But yeah, solvers are under-utilized in RE, I think they may have many interesting applications 🙂
nice 😀
what about remaining two from the same contest? have you tried?
Not really. Did you?
no, honestly I am a very beginner in RE. i just downloaded the tasks and now i am trying to do them, by following footsteps. that’s why I am asking, because I am curious to see how someone who is better than me did it. i will like to see the solution to the crackme with dll making, so if you know where to find the solution (if anyone did it) i would be thankful
Bartek (secnews.pl) is going to publish solutions (soon?).
Which crackme are you talking about? How did you try to solve it, where are you stuck?
Just for the record, Bartek has put the source code of all submissions to public: http://www.secnews.pl/2011/07/01/rozwiazania-konkursu-pimp-my-crackme/