Timing attacks [1] are an important subclass of side channel attacks used to reveal cryptographic secrets, basing only on time needed by targeted devices or applications to perform specific computations.

It turns out these attacks can be applied in a more prosaic context — instead of encryption keys, they can help us leak pointers to objects on the heap or, if we are lucky, in .code/.data sections of targeted application. Leaking a pointer with fixed RVA reveals the imagebase, so ASLR becomes ineffective (ROP). Leaking a heap pointer makes expoitation of WRITE-ANYWHERE bugs easier, so in both cases it’s a win :).
This post provides a high-level description of a POC implementation of a timing attack on hashtable used in Firefox (tested on v4, v13, v14). POC is quite fast (takes few secs) and leaks a heap pointer to a JS object. A detailed explanation will be provided in a different post (part 2).
The trick
Consider a hash table using double hashing [2]. In this scheme, keys are hashed like so:  mod
mod  , where
, where  ,
, 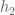 are hash functions and is the size of hash table. During insertion,
are hash functions and is the size of hash table. During insertion,  is incremented until a free slot is found, like shown below:
is incremented until a free slot is found, like shown below:

Lookups are performed the same way — is incremented until key value in a slot matches, or the slot is empty.
It’s easy to see that the execution time of  is proportional to the length of
is proportional to the length of 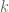 ‘s chain (number of collisions). In the above example
‘s chain (number of collisions). In the above example  , since there were two collisions. The idea is to use this fact to learn the value of key being looked up. Firefox is nice enough to store pointers and user supplied integers in the same hashtable (not always, but in specific circumstances), so we can control the table’s layout completely. It worth noting that only the object’s pointer is used in hashing, so
, since there were two collisions. The idea is to use this fact to learn the value of key being looked up. Firefox is nice enough to store pointers and user supplied integers in the same hashtable (not always, but in specific circumstances), so we can control the table’s layout completely. It worth noting that only the object’s pointer is used in hashing, so 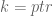 (contents of strings are not taken into account).
(contents of strings are not taken into account).
Here’s how we are going to layout keys inside the table (using JS integers):

Yellow slots are taken, white are free. We have to leave some free space, since FF grows / shrinks tables dynamically, basing on the number of taken slots.
If we keep generating JS objects (with different pointers) and trying to look them up in 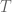 , we will finally find one that takes considerably longer than others to lookup. Let’s call this object
, we will finally find one that takes considerably longer than others to lookup. Let’s call this object  (M – max., str – string, since we are using strings (atoms, to be more precise) in POC) and the lookup time of :
(M – max., str – string, since we are using strings (atoms, to be more precise) in POC) and the lookup time of :  .
.
Here’s an example of a long chain for (Firefox uses subtraction instead of addition while hashing):

In this example  .
.
In order to find  , we will use the observation that
, we will use the observation that  divides
divides 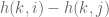 for any
for any 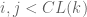 (this isn’t always true, but I’ll omit the second case for brevity). Indeed,
(this isn’t always true, but I’ll omit the second case for brevity). Indeed,  =
=  =
= 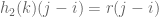 . If we collect enough of chain’s elements, we can calculate their differences and take
. If we collect enough of chain’s elements, we can calculate their differences and take  . This equality holds with high probability — chance of failure decreases exponentially with the number of collected elements (the most significant term of the exact formula is
. This equality holds with high probability — chance of failure decreases exponentially with the number of collected elements (the most significant term of the exact formula is 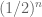 ).
).
How to find elements on ‘s chain? Remember that keys used to fill are integers. We can remove a key and check if  changed significantly. If it did, we know for shure that the removed key belongs to the chain.
changed significantly. If it did, we know for shure that the removed key belongs to the chain.
Here’s an example:

We removed 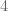 and this caused
and this caused  , so the lookup time after removal (
, so the lookup time after removal (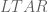 ) is going to be lower than
) is going to be lower than 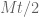 . In order to deal with inaccuracies of the JS clock (Date object), we will accept only elements for which
. In order to deal with inaccuracies of the JS clock (Date object), we will accept only elements for which  , so we are reducing our interest to the first half of the chain (red line on the diagram above). Without this restriction we would be unable to distinguish between keys that don’t belong to the chain and keys at the very end of it.
, so we are reducing our interest to the first half of the chain (red line on the diagram above). Without this restriction we would be unable to distinguish between keys that don’t belong to the chain and keys at the very end of it.
Obviously, removing keys one by one is too slow. Removing them in chunks in a bisect-like manner is better, but still has the running time proportional to . It’s faster to use a randomized algorithm. Let’s say we chose random elements to remove. Probability that we failed to hit any element of ‘s chain is  . The exponent is working in our favor, but we need to estimate
. The exponent is working in our favor, but we need to estimate  somehow, so that we don’t waste too much time —
somehow, so that we don’t waste too much time —  is as good as
is as good as 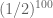 , but the second requires greater , so more elements to test.
, but the second requires greater , so more elements to test.
We can estimate by collecting integers with increasingly long chains, and using their lookup times to create a linear regression model [3]. Model will provide a linear function  that interpolates collected data. Estimating is then a matter of evaluating
that interpolates collected data. Estimating is then a matter of evaluating  . Below is an example of collected data points and a linear function that fits them best. Y axis is time and X is the chain’s length.
. Below is an example of collected data points and a linear function that fits them best. Y axis is time and X is the chain’s length.

Having we can pick so that  for any
for any 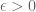 . After we finally pick , we chose random keys and remove them. If
. After we finally pick , we chose random keys and remove them. If 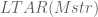 dropped below , it means that in the set we chose, there’s at least one key that belongs to the first part of the chain — we need to find it. In order to do so, we bisect the set of removed keys until only one is left. Running time:
dropped below , it means that in the set we chose, there’s at least one key that belongs to the first part of the chain — we need to find it. In order to do so, we bisect the set of removed keys until only one is left. Running time: 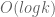 , if we disregard time necessary to add / remove keys from .
, if we disregard time necessary to add / remove keys from .
After collecting enough (8 in POC) elements of chain, we compute  . The only thing left is to find
. The only thing left is to find 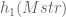 — the starting point.
— the starting point.
Recall ‘s layout:

Consider how changes, when removing two keys: 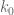 and
and 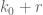 — we remove them separately and then measure .
— we remove them separately and then measure .
– if we remove 5 or 7, will not change, since 5, 7 do not belong to ‘s chain,
– removing 4 or 6 will cause 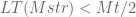 , since 4 and 6 are in the first half of chain,
, since 4 and 6 are in the first half of chain,
– removing 8 will cause and removing 10 will have no effect on .
These 3 conditions are sufficient to recognize if we are inside, outside, or and the edge of chain.
Algorithm to detect the starting point is simple. Start from element for which is smallest (so it’s the closest element to starting point). With we found earlier, do a binary search using the criteria above (inside, outside, hit) until hitting the edge (starting point).
With  and
and 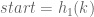 it’s possible to recover , which equals to
it’s possible to recover , which equals to  .
.
FIN
This is a simplified description. There’s quite a lot of details that were omitted in this post for brevity, but are required for this trick to work.
I suspect (this type of) timing attacks will be useful for leaking information not only from browsers. The most likely candidates seem to be kernels and perhaps even remote servers. (EDIT: I mean this in ASLR context, not secret-password context).
Here’s the POC. Download all files and open lol.html (in Firefox ;)) to see how it works. POC was tested on xp, w7 and linux. Send me an email if it doesn’t work for you.
1. http://en.wikipedia.org/wiki/Timing_attack
2. http://en.wikipedia.org/wiki/Double_hashing
3. http://en.wikipedia.org/wiki/Linear_regression







Timing attacks against hash tables on a remote server that is using java’s hashtables is possible. Build from Nate Lawson’s work on java string timing attacks, the hashtable is just an extension of that.
@Travis: link? Is the attack you mention about extracting passwords? I meant remotely leaking the imagebase, or weakening ASLR in any other way, so that it’s not necessary to use bruteforce in an exploit against, for example, apache.
His work proves its possible to time a string compare in java. Hashtables dont directly use string compares, until a collision occurs. The good news with hashtables its easy to create collisions (http://www.ocert.org/advisories/ocert-2011-003.html)
So once you have a collision the string compare timing attacks can begin (assuming its a table of strings)
An example attack is storing an admin’s cookie value in a hashtable. Since we can detect when a collision occurs (on the lookup), we can figure out what location in the hashtable the admin cookie is; then send requests to start the string compare timing attack (Nate Lawson’s paper) Thats the scenario I was able to do an auth bypass in.
I see. The difference here is that the string’s address is used to compute the hash, not the contents. This complicates things and creates a different scenario. I think similarities to Nate’s work end after filling the hash table.
Sorry, Didn’t mean to hijack your post. I was just trying to build off your comment here: “I suspect (this type of) timing attacks will be useful for leaking information not only from browsers. The most likely candidates seem to be kernels and perhaps even remote servers.” Just wanted to point out that its for sure possible against remote servers in some contexts
Thanks for mentioning Nate’s work and the hashDOS thing. I should’ve mention these in the post.
AWESOME work. See also: “Through The Side Channel” from PyCon. Similar hash timing attacks for python. http://python.mirocommunity.org/video/4251/pycon-2011-through-the-side-ch
@s7ephen: thanks, cool video.
See also BH 2007 timing attack against the balanced b-tree data structure http://www.coresecurity.com/content/timing-attacks